
Docker搭建常用中间件集群
MySQL主从复制
介绍
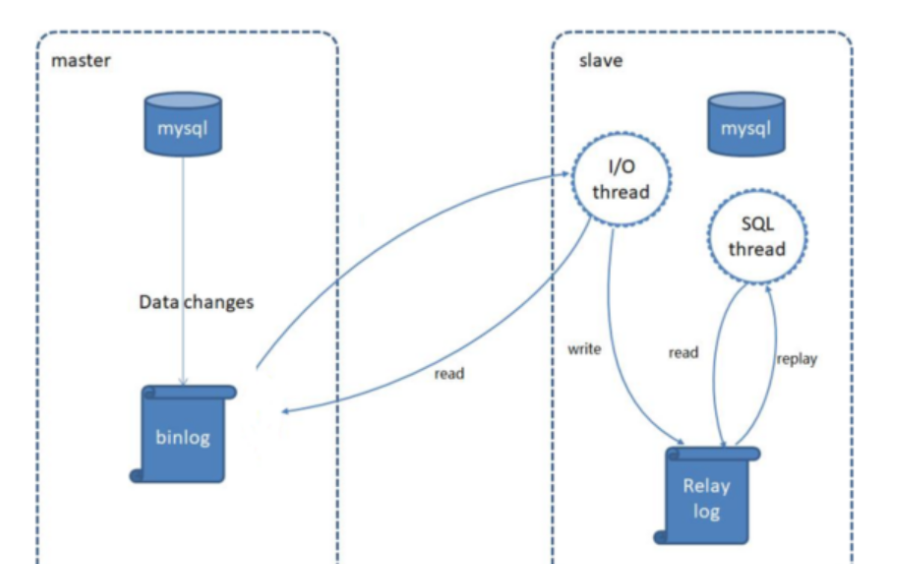
- MySQL数据库默认是支持主从复制的,不需要借助于其他的技术,我们只需要在数据库中简单的配置即可。
- MySQL主从复制是一个异步的复制过程,底层是基于Mysql数据库自带的 二进制日志 功能。就是一台或多台MySQL数据库 从另一台MySQL数据库进行日志的复制,然后再解析日志并应用到自身,最终实现 从库 的数据和 主库 的数据保持一致。MySQL主从复制是MySQL数据库自带功能,无需借助第三方工具。
- 二进制日志(BINLOG)记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但是不包括数据查询语句。此日志对于灾难时的数据恢复起着极其重要的作用,MySQL的主从复制, 就是通过该binlog实现的。默认MySQL是未开启该日志的。
- 简单来说就是一台服务器中的mysql数据库根据另一台服务器中的mysql数据库的日志文件进行分析然后执行sql语句进行数据复制。
集群实现
下载mysql:5.7镜像。
创建Master实例并启动,指定密码为root。
1
2
3
4
5
6docker run -p 3307:3306 --name mysql-master \
-v /home/cluster/mysql/master/conf:/etc/mysql \
-v /home/cluster/mysql/master/log:/var/log/mysql \
-v /home/cluster/mysql/master/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7创建slave实例并启动。
1
2
3
4
5
6docker run -p 3317:3306 --name mysql-slaver-01 \
-v /home/cluster/mysql/slaver/conf:/etc/mysql \
-v /home/cluster/mysql/slaver/log:/var/log/mysql \
-v /home/cluster/mysql/slaver/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.71
2
3
4
5
6参数说明
-p 3307:3306:将容器的3306端口映射到主机的3307端口
-v /home/cluster/mysql/master/conf:/etc/mysql:将配置文件夹挂在到主机
-v /home/cluster/mysql/master/log:/var/log/mysql:将日志文件夹挂载到主机
-v /home/cluster/mysql/master/data:/var/lib/mysql:将配置文件夹挂载到主机
-e MYSQL_ROOT_PASSWORD=root:初始化root用户的密码修改master配置。
1
vi /home/cluster/mysql/master/conf/my.cnf
注意:
skip-name-resolve一定要加,不然连接mysql会很慢1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
# 服务id,要保证唯一
server-id=1
log-bin=mysql-bin
read-only=0
# 要开启备份的数据库
binlog-do-db=db_test
# 要忽略备份的库
replicate-ignore-db=mysql
replicate-ignore-db=sys
replicate-ignore-db=performance_schema
replicate-ignore-db=information_schema修改salver配置。
1
vi /home/cluster/mysql/slaver/conf/my.cnf
注意:
skip-name-resolve一定要加,不然连接mysql会很慢1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
# 服务id,要保证唯一
server-id=2
log-bin=mysql-bin
read-only=1
# 要开启备份的数据库
binlog-do-db=gulimall_oms
# 要忽略备份的库
replicate-ignore-db=mysql
replicate-ignore-db=sys
replicate-ignore-db=performance_schema
replicate-ignore-db=information_schema重启:mysql-master和mysql-slaver-01
1
docker restart mysql-master mysql-slaver-01
1
2
3
4
5
6
7
8
9
10
11
docker exec -it mysql-master /bin/bash
2、mysql -uroot -p root
1)授权root可以远程访问(主从无关,方便我们可以远程链接mysql)
grant all privileges on *.* to 'root'@'%' IDENTIFIED BY 'root' with grant option;
flush privileges;
2)添加同步用户,链接master数据库,在master授权一个 复制权限的 用户
GRANT REPLICATION SLAVE ON *.* TO 'backup'@'%' IDENTIFIED BY '123456';
3、查看master状态,记录File名字:mysql-bin.000001,后面会用到
show master status;为master授权用户来他的同步数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15进入master容器。
docker exec -it mysql-master /bin/bash
登录mysql
mysql -uroot -proot
授权root可以远程访问(主从无关,方便我们可以远程链接mysql)
grant all privileges on *.* to 'root'@'%' IDENTIFIED BY 'root' with grant option;
flush privileges;
添加同步用户,链接master数据库,在master授权一个 复制权限的 用户
GRANT REPLICATION SLAVE ON *.* TO 'backup'@'%' IDENTIFIED BY '123456';
查看master状态,记录File名字:mysql-bin.000001,后面会用到
show master status;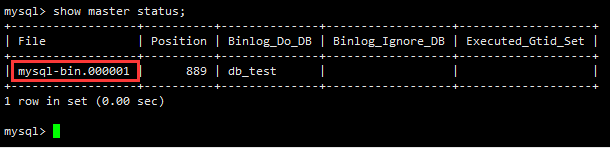
配置slaver同步master数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18进入slaver容器
docker exec -it mysql-slaver-01 /bin/bash
登录mysql
mysql -uroot -proot
授权root可以远程访问(主从无关,方便我们可以远程链接mysql)
grant all privileges on *.* to 'root'@'%' IDENTIFIED BY 'root' with grant option;
flush privileges;
设置主库连接
change master to master_host='192.168.50.247',master_user='backup',master_password='123456',master_log_file='mysql-bin.000001',master_log_pos=0,master_port=3307;
启动从库同步
start slave;
查看从库状态
show slave status;
redis-cluster集群模式
介绍
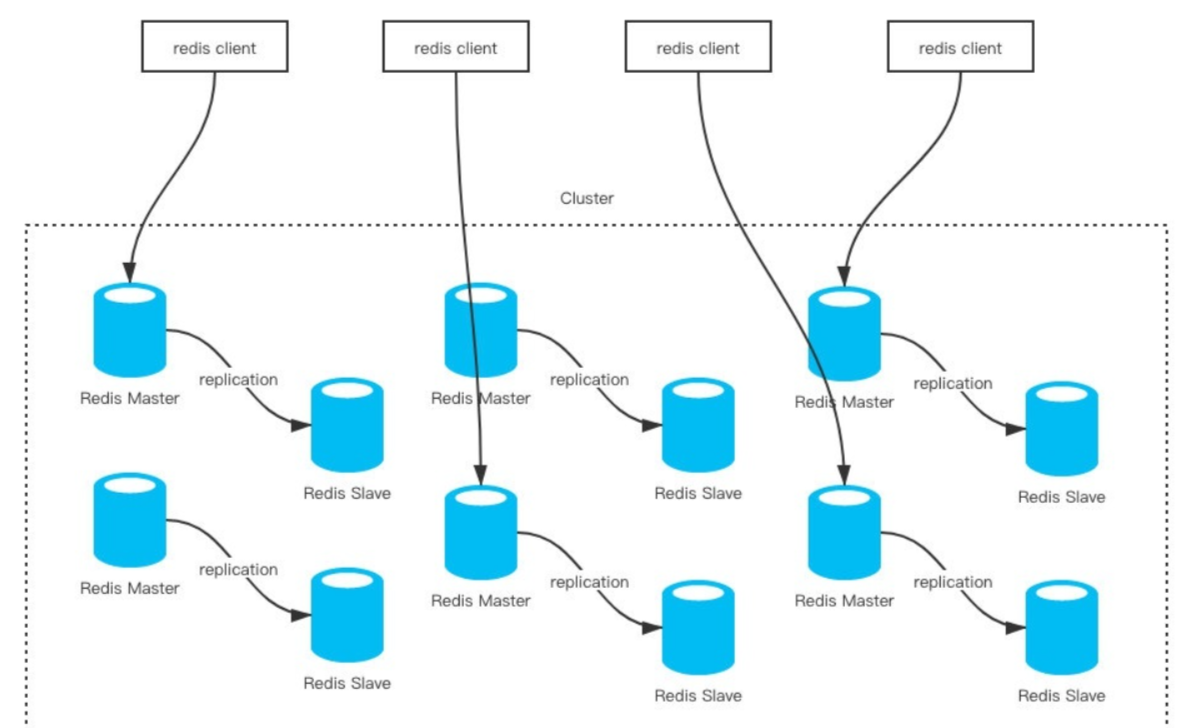
Redis的官方多机部署方案,Redis Cluster。一组Redis Cluster是由多个Redis实例组成,官方推荐我们使用6实例,其中3个为主节点,3个为从结点。一旦有主节点发生故障的时候,Redis Cluster可以选举出对应的从结点成为新的主节点继续对外服务,从而保证服务的高可用性。
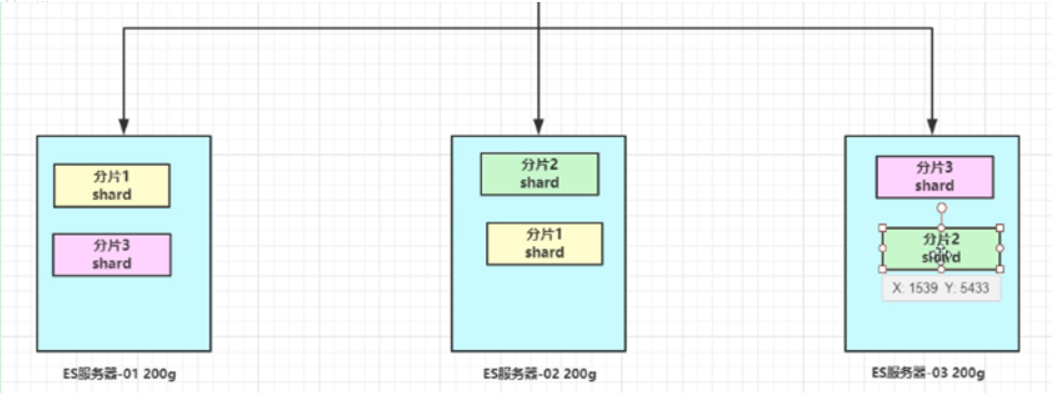
那么对于客户端来说,如何知道对应的key是要路由到哪一个节点呢?Redis Cluster把所有的数据划分为16384个不同的槽位,可以根据机器的性能把不同的槽位分配给不同的Redis实例,对于Redis实例来说,他们只会存储部分的Redis数据,当然,槽的数据是可以迁移的,不同的实例之间,可以通过一定的协议,进行数据迁移。一共16384个槽位,0~16383,对key使用JAVA CRC16校验算法,然后对16383求余,算出槽位。这是一个重定向过程,如果当前节点与对应槽位没有包含关系,则重定向发送至下一节点重新判断。
优点:分片+高可用都实现,相当于mysql的分库分表。
缺点和需要预防的问题:
- key批量操作支持有限,不再同一槽位的批量操作不再同一节点,不支持。类似mset、mget 操作,目前只支持对具有相同slot值的key执行批量操作。对于映射为不同slot值的key由于执行mget、mget等操作可能存在于多个节点上,因此不被支持。
- key事务操作支持有限,事务应使用lua脚本不使用redis事务。
- 只支持多key在同一节点上的事务操作,当多个key 分布在不同的节点上时无法使用事务功能。|
- key 作为数据分区的最小粒度。
- 不能将一个大的键值对象如 hash、list等映射到不同的节点。
- 不支持多数据库空间,单机下的 Redis可以支持16个数据库((db0~ db15),集群模式下只能使用一个数据库空间,即db0。
- 复制结构只支持一层,只有一层主从,没有更多,从节点只能复制主节点,不支持嵌套树状复制结构。
- 命令大多会重定向,耗时多。
集群实现
数据分区,3主3从,从为了同步备份,主进行slot数据分片。
- 高可用:主机宕机从机替代。
- 数据分片:槽机制。
- 容灾备份:主从备份。
创建6份配置文件+启动6个redis
1 | for port in $(seq 7001 7006); \ |

建立集群,进入一个master节点并设置每个节点1个副本
从6个节点挑出3个主节点,然后给每个主节点挑一个从节点
1 | docker exec -it redis-7001 /bin/bash |
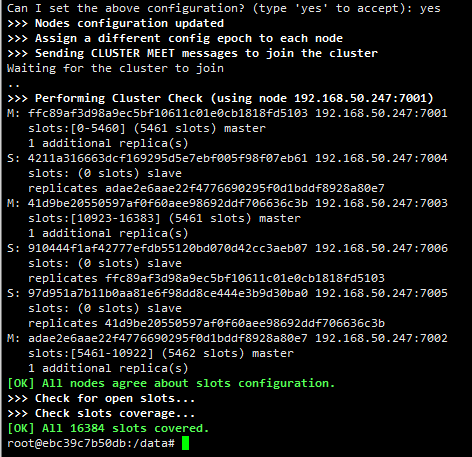
1 | redis-cli --cluster create 192.168.50.247:7001 192.168.50.247:7002 192.168.50.247:7003 192.168.50.247:7004 192.168.50.247:7005 192.168.50.247:7006 --cluster-replicas 1 |
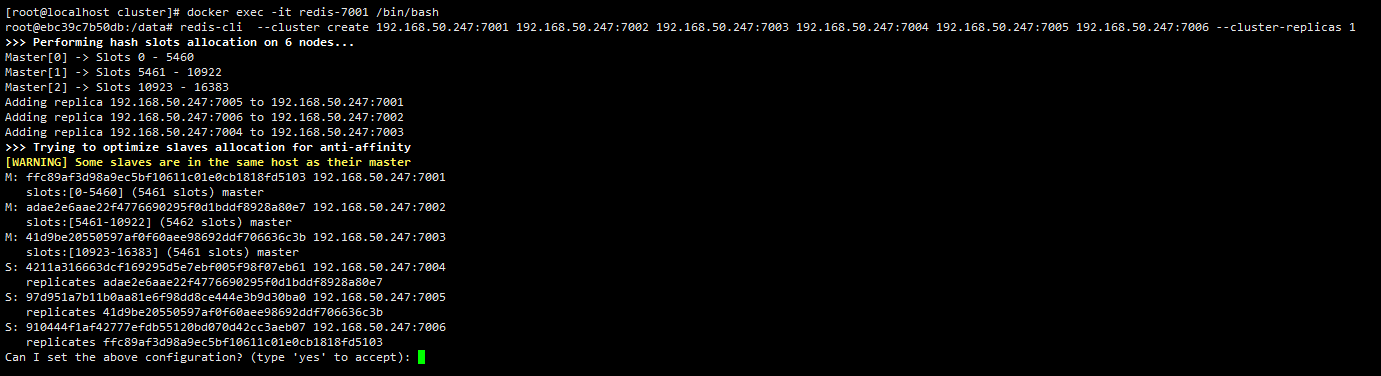
可以看到redis自动帮我们分配了3个主节点,分别是7001、7002和7003,7001的从节点是7006,7002的从节点是7004,7003的从节点是7005。
输入yes后redis就会按照上述安排帮我们建立集群。
测试集群
连入集群,要加-c
1
redis-cli -c -h 192.168.50.247 -p 7001

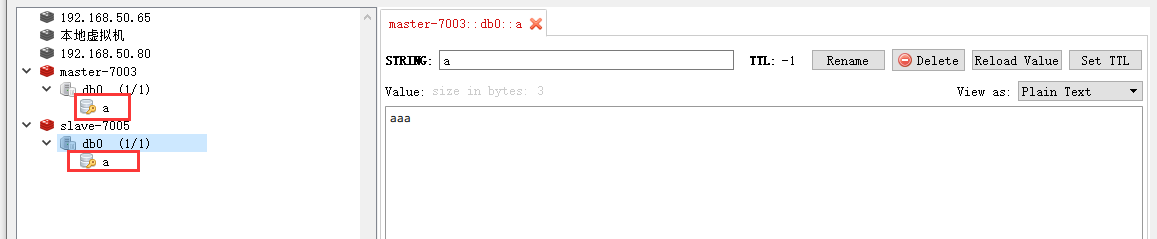
可以看到,当在7001机器上保存一个数据时,redis自动切换到了7003这台机器上,这就是redis重定向了其他槽了。数据保存在7003这台机器上的,我们可以看一下7003的从节点7005有没有数据同步。
模拟宕机
1
2
3
4
5查看集群状态
cluster info
查看集群节点信息
cluster nodes

可以看到7001是master节点,7006是7001的slave节点,接下来我们停掉7001机器。
1 | docker stop redis-7001 |

再次查看集群几点信息,发现7001机器已经是fail状态了,7006晋升成为了master节点。再次启动7001节点。
1 | docker start redis-7001 |

可以发现7001节点成为了7006的从节点了。
Elasticsearch集群搭建-节点+分片
介绍
elasticsearch是天生支持集群的,他不需要依赖其他的服务发现和注册的组件,如zookeeper这些,因为他内置了一个名字叫ZenDiscovery的模块,是elasticsearch,自己实现的一套用于节点发现和选主等功能的组件,所以elasticsearch做起集群来非常简单,不需要太多额外的配置和安装额外的第三方组件。
要求:
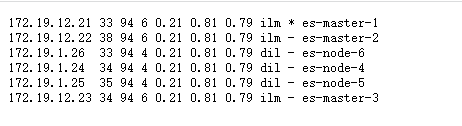
- 6台物理机6个节点,3个master节点3个data节点【角色分离,防止脑裂】。
- 判定时间设为10秒。
- 设置discover.zen.minimum_master_nodes=2,只要一个master宕机,另外两个就可以选举。
master节点上
1 | node.master = true |
只要集群名字是一样的,就会自动加入到同一个集群中
集群实现
先修改jvm线程数,防止启动es报错
1 | sysctl -w vm.max_map_count=262144 |
准备docker网络
1 | #查看docker网络 |
利用docker模拟6台物理机,创建每一个容器使用一个ip
创建主节点
1 | for port in $(seq 1 3); \ |
创建数据节点
1 | for port in $(seq 4 6); \ |
访问查看集群相关信息指令
1 | 查看健康状况 |
RabbitMQ集群
RabbiMQ是用Erlang开发的,集群非常方便,因为Erlang,天生就是一门分布式语言,但其本身并不支持负载均衡。需要nginx
RabbitMQ集群中节点包括内存节点(RAM)、磁盘节点(Disk,消息持久化),集群中至少有一个Disk 节点。
普通集群模式
- 普通模式中集群不会同步消息,只会同步queue、exchange。
- demo:3个节点A\B\C组成的集群,消费节点C上的队列,如果此时消息在节点A的队列上,集群会将A的信息发送到C的队列上供于消费
缺点:单点故障无法解决,无法做到高可用。 - 对于普通模式,集群中各节点有相同的队列结构,但消息只会存在于集群中的一个节点。对于消费者来说,若消息进入A节点的Queue中,当从B节点拉取时,RabbitMQ会将消息从A中取出,并经过B发送给消费者。应用场景:该模式各适合于消息无需持久化的场合,如日志队列。当队列非持久化,且创建该队列的节点宕机,客户端才可以重连集群其他节点,并重新创建队列。若为持久化.只能等故障节点恢复。
镜像集群模式
与普通模式不同之处是消息实体会主动在镜像节点间同步,而不是在取数据时临时拉取,高可用;该模式下,mirror queue有一套选举算法,即1个master、n个slaver,生产者、消费者的请求都会转至master。应用场景:可靠性要求较高场合,如下单、库存队列。
优点:解决了高可用,当消息进入节点A的队列,会同步到B\C。当master A节点宕机,B、C会选择一个主节点
- 镜像模式由主节点接收 生产者和消费者的请求【代理】
- 镜像模式 依赖于 先搭建一个普通模式,再设置成镜像模式
缺点:若镜像队列过多,且消息体量大,集群内部网络带宽将会被此种同步通讯所消耗。
搭建镜像集群
创建文件夹
1
2
3mkdir /home/cluster/rabbitmq
cd /home/cluster/rabbitmq
mkdir rabbitmq01 rabbitmq02 rabbitmq03启动3个rabbitmq
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20docker run -d --hostname rabbitmq01 --name rabbitmq01 \
-v /home/cluster/rabbitmq/rabbitmq01:/var/lib/rabbitmq \
-p 15673:15672 -p 5673:5672 \
-e RABBITMQ_ERLANG_COOKIE='abcdefg' rabbitmq:management
docker run -d --hostname rabbitmq02 --name rabbitmq02 \
-v /home/cluster/rabbitmq/rabbitmq02:/var/lib/rabbitmq \
-p 15674:15672 -p 5674:5672 \
-e RABBITMQ_ERLANG_COOKIE='abcdefg' \
--link rabbitmq01:rabbitmq01 rabbitmq:management
docker run -d --hostname rabbitmq03 --name rabbitmq03 \
-v /home/cluster/rabbitmq/rabbitmq03:/var/lib/rabbitmq \
-p 15675:15672 -p 5675:5672 \
-e RABBITMQ_ERLANG_COOKIE='abcdefg' \
--link rabbitmq01:rabbitmq01 \
--link rabbitmq02:rabbitmq02 rabbitmq:management
赋予所有文件权限
chmod -R 777 /home/cluster/rabbitmq/1
2
3
4
5设置容器的主机名
--hostname
节点认证作用,部署集成时需要同步该值
RABBITMQ_ERLANG_COOKIE节点加入集群
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26进入个节点完成初始化
docker exec -it rabbitmq01 /bin/bash
rabbitmqctl stop_app
恢复出厂设置
rabbitmqctl reset
rabbitmqctl start_app
exit
将节点2加入到集群
docker exec -it rabbitmq02 /bin/bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbitmq01
rabbitmqctl start_app
exit
将节点3加入到集群
docker exec -it rabbitmq03 /bin/bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbitmq01
rabbitmqctl start_app
exit
3)访问192.168.50.247:15673查看集群
随便访问一个就可以15673、15674、15675都可以实现镜像集群
1
2
3
4
5
6
7
8
9#随便进入一个容器
docker exec -it rabbitmq01 /bin/bash
#设置一个策略,/:当前主机,策略名字是ha,^指的是当前所有主机都是高可用模式[^hello 指hello开头的所有主机],自动同步
rabbitmqctl set_policy -p / ha "^" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
exit
# 查看vhost/下面的所有policy
rabbitmqctl list_policies -p /验证集群
- 创建一个queue。
- 生产一个消息,3个节点都能看到该消息。
- 消费消息,3个节点的queue上消息都不存在了。
 微信
微信 支付宝
支付宝